
剧透特斯拉将在AI Day上发布的超级计算芯片?
前不久,马斯克发推特宣布了特斯拉「AI Day」将在北美时间 8 月 19 日正式举行。
此次 AI Day,马斯克将会特斯拉在人工智能领域的软件和硬件进展,尤其在(神经网络)的训练和预测推理方面。这次活动的另外一个目的就是招揽相关人才。
在「AI Day」发布会的邀请函上,放着一张芯片图。

从图上估测,该芯片采用了非常规的封装形式,第一层和第五层铜质结构是水冷散热模块;红色圈出的第二层结构由 5*5 阵列共 25 个芯片组成;第三层为 25 个阵列核心的 BGA(球栅阵列)封装基板;第四层和第七层应该只是物理承载结构附带一些导热属性;蓝色圈出的第六层应该是功率模块,以及上面竖着的黑色长条,很可能是穿过散热层与芯片进行高速通信的互联模块。
从第二层结构的圆形边角,以及拥有 25 个芯片结构来看,非常像 Cerebras 公司的 WSE 超大处理器,猜测特斯拉可能采用了 TSMC(台积电)的 InFo-SoW(集成扇出系统)设计。

所谓 InFo-SoW 设计,简单理解来说就是原本一个晶圆(Wafer)能够「切割」出很多个芯片,做成很多个 CPU/GPU 等类型的芯片(根据设计不同,光刻时决定芯片类型),而 InFo-SoW 则是所有的芯片都来自于同一个晶圆,不但不进行切割,反而是直接将整个晶圆做成一个超大芯片,实现 system on wafer 的设计。

这么做的好处有三个:极低的通讯延迟;超大的通讯带宽;能效的提升。
简单来说,由于芯片与芯片之间的物理距离极短,加上通讯结构可以直接在晶圆上布置,使得所有内核都能使用统一的 2D 网状结构互连,实现了芯片与芯片间通信的超低延迟和高带宽;以及由于结构优势实现了较低的 PDN 阻抗,实现了能效的提升。此外,由于是阵列多个小芯片组成,可以通过冗余设计来避免「良品率」问题,以及实现小芯片处理的灵活性。
举个形象的例子,特斯拉前一阵公布的超级电脑(用于训练自动驾驶和自动驾驶能力的深度神经网络),一共用了 5760 个 NVIDIA A100 80GB 的 GPU,那么在这些芯片之间,需要海量的物理结构进行连接以实现通讯,不仅耗费大量成本,且由于连接结构的带宽限制成为「木桶短板」,导致整体效率较低,并且还有分散的庞大散热问题。

这里拿 Cerebras 的 WSE-2 作为参考对比,一个芯片的核心数是 NVIDIA A100 的 123 倍,芯片缓存为 1000 倍,缓存带宽为 12733 倍,Fabric 结构带宽则为 45833 倍。
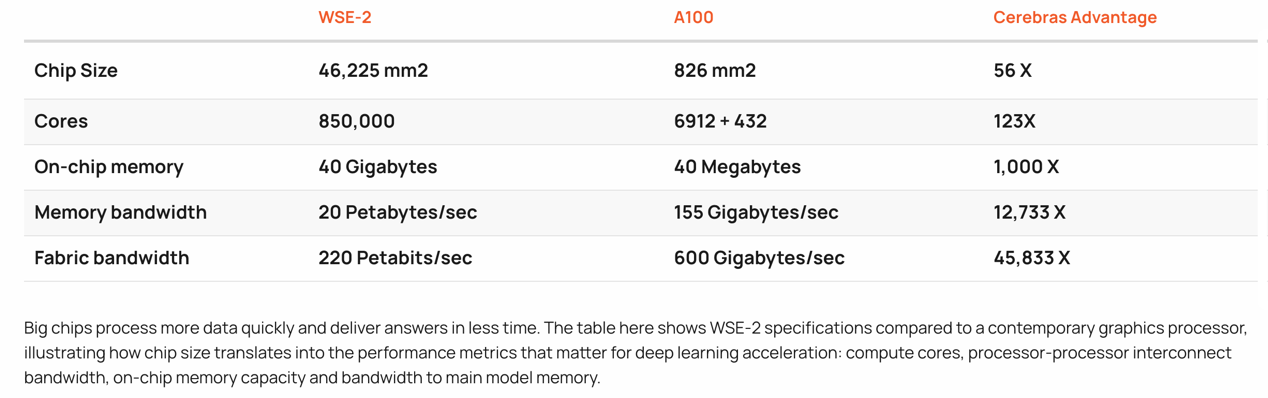
这样级别的性能怪兽其主要目的,就是为了 AI 的数据处理和训练。
所以不难推断出,「AI Day」邀请函上放出的这张图,应该就是马斯克所谓的 Dojo 超级计算机的自研芯片。并且颇有意思的是,发布会的时间是 2021 年 8 月 19 日,而就在刚好一年前的 2020 年 8 月 19 日,马斯克发了一条推特说:「Dojo V1.0 还未完成,估计还需要一年的时间。不仅仅是芯片本身的研发难度,能效和冷却问题也非常的难。」

之所以说冷却问题难,是因为根据标准晶圆一块是 300mm 来看,那么特斯拉这块 Dojo 芯片设计单个芯片应该与英伟达 RTX 3090 差不多,至少每个芯片有 280 亿-320 亿个左右的晶体管,单个芯片功耗可达 250W-300W 左右,整体功耗约在 6250W-7500W 左右;并且台积电也曾说 InFo-SoW 设计的最高功耗约为 7000W,同样印证了这一点。
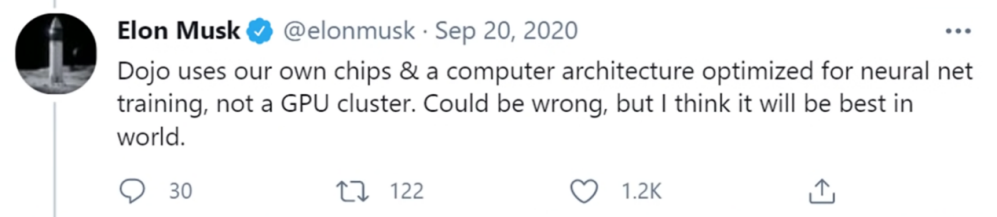
几个月后,马斯克又补充说:「Dojo 采用我们自研的芯片和为神经网络训练优化的计算架构,而非 GPU 集群。尽管可能是不准确的,但是我认为 Dojo 将会是世界上最棒的超算。」
并且,马斯克在 2021 年特斯拉 Q1 财报时也曾说:「Dojo 是一台为神经网络训练优化的超级计算机。我们认为以视频数据处理速度而言,Dojo 将会是全世界效率最高的。」
到底马斯克会在即将到来的 AI Day 上发布一款怎样的超级计算机,敬请关注汽车之心的报道。
0
分享
好文章,需要你的鼓励













参与评论
请您注册或者登录汽车之心社区账号即可发表回复
去登录
相关评论(共0条)
查看更多评论